Purchasing a new computer is all fun and games until you have to set it up. You’ve just opened up your brand spanking new machine and you want to play with it, but you can’t do that until you get everything you need installed. What do you do if you’ve just installed your favorite GNU/Linux distribution when a shiny, new one comes along? You were finally getting comfortable and the last thing you want to do is fight through the hassle of setting up your environment again.
Instead of sloshing through the installation of all those dependencies, you can take a little bit of time to setup a .dotfiles repository. What are .dotfiles? They’re those hidden files in your home folder that manage your profile configuration. You don’t need all of them, but a few can go a long ways. Take a look at mine. Whenever I’m setting up a new machine, the first thing I do is install git. From there, I can pull down my version controlled configuration, and be up and running in minutes. Let’s do a breakdown of each file.
.bash_aliases
# shortcuts
alias lh=’ls -lha’
alias plz=’sudo $(history -p \!\!)’
alias codecept=”php vendor/bin/codecept”
# Change directories aliases
alias cdot=’cd ~/.dotfiles’;
alias cdtox=’cd ~/Dev/projects/mine/tox’;
alias cdhack=’cd ~/Dev/vvv/www/hack/public_html/wp-content’
alias cdintra=’cd ~/Dev/projects/kalix’;
alias cdvvv=’cd ~/Dev/vvv’;
alias cdans=’cd ~/Dev/ans’;
# Apps
alias postman=’/usr/bin/PostmanCanary’
# Compress JPGs into directory
alias compress=’mkdir compressed;for photos in *.jpg;do convert -verbose “$photos” -quality 85% -resize 1920×1080 ./compressed/”$photos”; done’
As you can see, keeping useful comments in your .dotfiles can make maintenance easier. You’ll notice a few aliases that I have for frequently used commands, followed by a few more aliases that take me to frequently accessed directories. Lastly, you’ll notice a familiar command I use when compressing images.
.bashrc
# ~/.bashrc: executed by bash(1) for non-login shells.
# see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
# for examples
# If not running interactively, don’t do anything
case $- in
*i*) ;;
*) return;;
esac
# don’t put duplicate lines or lines starting with space in the history.
# See bash(1) for more options
HISTCONTROL=ignoreboth
# append to the history file, don’t overwrite it
shopt -s histappend
# for setting history length see HISTSIZE and HISTFILESIZE in bash(1)
HISTSIZE=1000
HISTFILESIZE=2000
# check the window size after each command and, if necessary,
# update the values of LINES and COLUMNS.
shopt -s checkwinsize
# If set, the pattern “**” used in a pathname expansion context will
# match all files and zero or more directories and subdirectories.
#shopt -s globstar
# make less more friendly for non-text input files, see lesspipe(1)
[ -x /usr/bin/lesspipe ] && eval “$(SHELL=/bin/sh lesspipe)”
# set variable identifying the chroot you work in (used in the prompt below)
if [ -z “${debian_chroot:-}” ] && [ -r /etc/debian_chroot ]; then
debian_chroot=$(cat /etc/debian_chroot)
fi
# set a fancy prompt (non-color, unless we know we “want” color)
case “$TERM” in
xterm-color|*-256color) color_prompt=yes;;
esac
# uncomment for a colored prompt, if the terminal has the capability; turned
# off by default to not distract the user: the focus in a terminal window
# should be on the output of commands, not on the prompt
#force_color_prompt=yes
if [ -n “$force_color_prompt” ]; then
if [ -x /usr/bin/tput ] && tput setaf 1 >&/dev/null; then
# We have color support; assume it’s compliant with Ecma-48
# (ISO/IEC-6429). (Lack of such support is extremely rare, and such
# a case would tend to support setf rather than setaf.)
color_prompt=yes
else
color_prompt=
fi
fi
# Add git branch if its present to PS1
parse_git_branch() {
git branch 2> /dev/null | sed -e ‘/^[^*]/d’ -e ‘s/* \(.*\)/(\1)/’
}
if [ “$color_prompt” = yes ]; then
PS1=’${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[01;31m\] $(parse_git_branch)\[\033[00m\]\$ ‘
else
PS1=’${debian_chroot:+($debian_chroot)}\u@\h:\w $(parse_git_branch)\$ ‘
fi
# If this is an xterm set the title to user@host:dir
case “$TERM” in
xterm*|rxvt*)
PS1=”\[\e]0;${debian_chroot:+($debian_chroot)}\u@\h: \w\a\]$PS1″
;;
*)
;;
esac
# enable vi shortcuts
set -o vi
# enable color support of ls and also add handy aliases
if [ -x /usr/bin/dircolors ]; then
test -r ~/.dircolors && eval “$(dircolors -b ~/.dircolors)” || eval “$(dircolors -b)”
alias ls=’ls –color=auto’
#alias dir=’dir –color=auto’
#alias vdir=’vdir –color=auto’
alias grep=’grep –color=auto’
alias fgrep=’fgrep –color=auto’
alias egrep=’egrep –color=auto’
fi
# colored GCC warnings and errors
#export GCC_COLORS=’error=01;31:warning=01;35:note=01;36:caret=01;32:locus=01:quote=01′
# some more ls aliases
alias ll=’ls -alF’
alias la=’ls -A’
alias l=’ls -CF’
# Add an “alert” alias for long running commands. Use like so:
# sleep 10; alert
alias alert=’notify-send –urgency=low -i “$([ $? = 0 ] && echo terminal || echo error)” “$(history|tail -n1|sed -e ‘\”s/^\s*[0-9]\+\s*//;s/[;&|]\s*alert$//’\”)”‘
# Alias definitions.
# You may want to put all your additions into a separate file like
# ~/.bash_aliases, instead of adding them here directly.
# See /usr/share/doc/bash-doc/examples in the bash-doc package.
if [ -f ~/.bash_aliases ]; then
. ~/.bash_aliases
fi
# enable programmable completion features (you don’t need to enable
# this, if it’s already enabled in /etc/bash.bashrc and /etc/profile
# sources /etc/bash.bashrc).
if ! shopt -oq posix; then
if [ -f /usr/share/bash-completion/bash_completion ]; then
. /usr/share/bash-completion/bash_completion
elif [ -f /etc/bash_completion ]; then
. /etc/bash_completion
fi
fi
# disable Software Flow Control
stty -ixon
For the most part, this is a standard .bashrc file. The part that I find most helpful is the portion that shows me whatever git branch I’m on in the current directory (provided there is a git repo in the directory).
.vimrc
set nocompatible ” be iMproved, required
filetype off ” required
set number
set tabstop=4
set softtabstop=0 noexpandtab
set shiftwidth=4
set autochdir
set wildignore+=vendor/**,mail/**,runtime/**
let $BASH_ENV = “~/.bash_aliases”
syntax on
” set the runtime path to include Vundle and initialize
set rtp+=~/.vim/bundle/Vundle.vim
call vundle#begin()
” alternatively, pass a path where Vundle should install plugins
“call vundle#begin(‘~/some/path/here’)
” let Vundle manage Vundle, required
Plugin ‘VundleVim/Vundle.vim’
” Color scheme
Plugin ‘morhetz/gruvbox’
” File Tree
Plugin ‘scrooloose/nerdtree’
” Search files
Plugin ‘ctrlpvim/ctrlp.vim’
” Install ripgrep as well (https://github.com/BurntSushi/ripgrep)
Plugin ‘dyng/ctrlsf.vim’
” Multi-cursor support
Plugin ‘terryma/vim-multiple-cursors’
” Surrounding tags
Plugin ‘tpope/vim-surround’
” Upgraded status line
Plugin ‘itchyny/lightline.vim’
” Syntax checks
Plugin ‘vim-syntastic/syntastic’
” Git
Plugin ‘tpope/vim-fugitive’
” auto-complete
Plugin ‘Valloric/YouCompleteMe’
” All of your Plugins must be added before the following line
call vundle#end() ” required
filetype plugin indent on ” required
” To ignore plugin indent changes, instead use:
“filetype plugin on
”
” Brief help
” :PluginList – lists configured plugins
” :PluginInstall – installs plugins; append `!` to update or just :PluginUpdate
” :PluginSearch foo – searches for foo; append `!` to refresh local cache
” :PluginClean – confirms removal of unused plugins; append `!` to auto-approve removal
”
” see :h vundle for more details or wiki for FAQ
” Put your non-Plugin stuff after this line
colorscheme gruvbox
set background=dark
” Python path (required for autocomplete plugin)
” let g:python3_host_prog = ‘c:\\Users\\dylan\\AppData\\Local\\Programs\\Python\\Python37-32\\python.exe’
set encoding=utf-8
” Auto start NERDtree
autocmd vimenter * NERDTree
map <C-k> :NERDTreeToggle<CR>
autocmd BufEnter * if (winnr(“$”) == 1 && exists(“b:NERDTree”) && b:NERDTree.isTabTree()) | q | endif
let g:NERDTreeNodeDelimiter = “\u00a0″
let g:NERDTreeShowHidden = 1
” search settings
let g:ctrlsf_default_root = ‘project’
let g:ctrlsf_position = ‘bottom’
let g:ctrlsf_default_view_mode = ‘compact’
let g:ctrlp_custom_ignore = {
\ ‘dir’: ‘vendor\|.git\$’
\}
” code quality
set statusline+=%#warningmsg#
set statusline+=%{SyntasticStatuslineFlag()}
set statusline+=%*
let g:syntastic_always_populate_loc_list = 1
let g:syntastic_auto_loc_list = 1
let g:syntastic_check_on_open = 1
let g:syntastic_check_on_wq = 1
” status line config
set noshowmode
let g:lightline = {
\ ‘active’: {
\ ‘left’: [ [ ‘mode’, ‘paste’ ],
\ [ ‘gitbranch’, ‘readonly’, ‘filename’, ‘modified’ ] ],
\ ‘right’: [ [ ‘lineinfo’ ], [’absolutepath’] ]
\ },
\ ‘component_function’: {
\ ‘gitbranch’: ‘fugitive#head’
\ },
\ }
” YouCompleteMe Options
let g:ycm_disable_for_files_larger_than_kb = 1000
” autoinsert closing brackets
“inoremap ” “”<left>
“inoremap ‘ ”<left>
“inoremap ( ()<left>
“inoremap [ []<left>
inoremap { {}<left>
inoremap {<CR> {<CR>}<ESC>O
inoremap {;<CR> {<CR>};<ESC>O
” nvim terminal options
” To map <Esc> to exit terminal-mode: >
:tnoremap <Esc> <C-\><C-n>
” To use `ALT+{h,j,k,l}` to navigate windows from any mode: >
:tnoremap <A-h> <C-\><C-N><C-w>h
:tnoremap <A-j> <C-\><C-N><C-w>j
:tnoremap <A-k> <C-\><C-N><C-w>k
:tnoremap <A-l> <C-\><C-N><C-w>l
:inoremap <A-h> <C-\><C-N><C-w>h
:inoremap <A-j> <C-\><C-N><C-w>j
:inoremap <A-k> <C-\><C-N><C-w>k
:inoremap <A-l> <C-\><C-N><C-w>l
:nnoremap <A-h> <C-w>h
:nnoremap <A-j> <C-w>j
:nnoremap <A-k> <C-w>k
:nnoremap <A-l> <C-w>l
” don’t show warning on terminal exit
set nomodified
This file is the entire reason I started tracking my .dotfiles. Being able to effortlessly pull down my programming environment makes switching to a new computer so much simpler. Most of this file concerns the installation of various Vim plugins using Vundle but there are a few keyboard shortcuts as well. I’ll save preaching about Vim for another post.
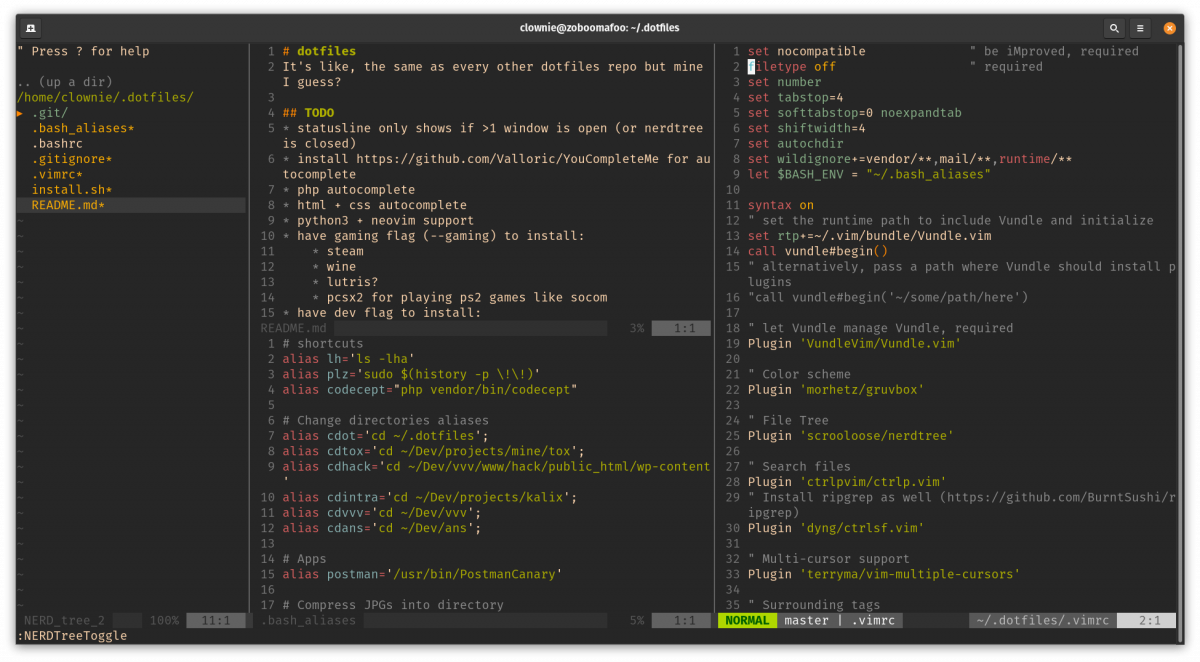
Vim in action
install.sh
#!/bin/bash
ln -sf ~/.dotfiles/.bashrc ~/.bashrc
ln -sf ~/.dotfiles/.vimrc ~/.vimrc
ln -sf ~/.dotfiles/.bash_aliases ~/.bash_aliases
# php
sudo add-apt-repository ppa:ondrej/php
sudo add-apt-repository ppa:jtaylor/keepass
sudo apt-get update
sudo apt-get install -y python3 curl wget software-properties-common ansible vim vim-gtk3 git ripgrep build-essential cmake wireguard php7.4 php7.4-curl php7.4-gd php7.4-json php7.4-mbstring php7.4-xml keepass2 imagemagick neovim vim-nox python3-dev
# neovim
echo “set runtimepath^=~/.vim runtimepath+=~/.vim/after” >> ~/.config/nvim/init.vim
echo “let &packpath = &runtimepath” >> ~/.config/nvim/init.vim
echo “source ~/.vimrc” >> ~/.config/nvim/init.vim
# composer
# double check if hash has changed
php -r “copy(‘https://getcomposer.org/installer’, ‘composer-setup.php’);”
php -r “if (hash_file(‘sha384’, ‘composer-setup.php’) === ‘e5325b19b381bfd88ce90a5ddb7823406b2a38cff6bb704b0acc289a09c8128d4a8ce2bbafcd1fcbdc38666422fe2806’) { echo ‘Installer verified’; } else { echo ‘Installer corrupt’; unlink(‘composer-setup.php’); } echo PHP_EOL;”
php composer-setup.php
php -r “unlink(‘composer-setup.php’);”
sudo mv composer.phar /usr/local/bin/composer
sudo chown root:root /usr/local/bin/composer
While my .vimrc is what convinced me to start a .dotfiles repo, the install.sh is by far the most useful file in the entire project. When this file is run, the first thing it does is connect my .bashrc, .vimrc, and .bash_aliases to my profile. It will then add a couple of repositories, update the repositories, and install most everything I need to get up and running. Whenever I find myself installing another useful package on my machine, I try to remember to add it here as well so that I’ll have it in the future. After the installation of commonly used packages, I’ll setup Neovim and download composer for PHP dependency management. Interestingly enough, this process always breaks because I never have the correct hash to compare the updated composer.phar file to.
README
While this may not seem important, I can assure you that it’s the most important file in the entire repository. My README file tracks changes, documents proper installation techniques, and gives me a heads up about any quirks I might run into. You will always appreciate having documentation later so take the time to keep up with this one.
Conclusion
Managing a .dotfiles repository is by no means a one-off project. It’s an ever-changing entity that will follow you wherever you go and be whatever you need it to be. Use it as you need it, but if you take care of it, it will take care of you. You’ll thank yourself later on for putting in the work now. For more information, check out http://dotfiles.github.io/ or do some quick searching on the interwebs to find tons of other examples.